Wieder mal CC statt BCC? Einblick in fremde Kundenstämme
Wenn schon Datenschutzpanne, dann wenigstens mit Mehrwert
- Christian Süßenguth
- Kurz notiert

Wer kennt es nicht – "versehentlich" landet wieder eine Mail in tausenden Postfächern, bei denen für einen Newsletter die Empfänger:innen nicht ins BCC-Feld, sondern ins CC-Feld gepackt wurden. Und im Handumdrehen ist das "Missgeschick" zu einer waschechten Datenschutzpanne geworden.
Und weil viele Unternehmen leider immer noch nicht begriffen haben, dass alle Rundmails an mehr als 10 Personen grundsätzlich und ausschließlich über ein geeignetes Newsletter-System verschickt werden sollten, ist die Bequemlichkeit leider noch viel zu oft der Sieger – zum Leidwesen aller Betroffenen. Und weil wir wohl mit dieser Art von "Panne" auch weiterhin werden leben müssen, verschafft sie uns mit meinem Script wenigstens etwas mehr Transparenz.
Als "Teil-Geschädigter" stehe ich am anderen Ende der Kette und habe leider keinerlei Einfluss auf den Umgang mit meinen Daten durch das verursachende Unternehmen. Und weil es außer den üblichen "Datenschutz ist uns wichtig"-Entschuldigungsmails keine wirkliche "Entschädigung" gibt, habe ich kurzerhand ein kleines Script geschrieben, was einen aufschlussreichen Überblick über die Kunden des Versenders erzeugt. Denn im Sinne der Transparenz kann es ja doch recht hilfreich und spannend sein, einen Einblick in einen fremden Kundenstamm zu erhalten. 😜
Ablauf und Vorbereitungen
Der Ablauf ist ganz einfach:
Du erhältst eine E-Mail, in welcher massenhaft E-Mailadressen im "CC-Feld" oder sogar im "An"-Feld stehen. Lass dir zunächst den Quelltext dieser Mail anzeigen.
Kopiere daraus alle Empfänger:innen in eine leere Textdatei mit dem Namen urls.txt und bearbeite diese so lange mit "Suchen-und-Ersetzen", bis du am Ende eine Liste mit allen URLs (Domains) der Empfänger:innen erhältst.
Unter Linux/Windows und macOS empfehle ich dir dafür einen Editor wie Sublime Text. Alternativ kannst du unter Windows auch Notepad++ oder unter macOS CotEditor verwenden.
Dabei wählst du mit folgendem "RegEx" zuerst alle E-Mailadressen aus und kopierst diese anschließend in die Zwischenablage:
(?:[a-z0-9!#$%&'*+/=?^_`{|}~-]+(?:\.[a-z0-9!#$%&'*+/=?^_`{|}~-]+)*|"(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21\x23-\x5b\x5d-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])*")@(?:(?:[a-z0-9](?:[a-z0-9-]*[a-z0-9])?\.)+[a-z0-9](?:[a-z0-9-]*[a-z0-9])?|\[(?:(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?)\.){3}(?:25[0-5]|2[0-4][0-9]|[01]?[0-9][0-9]?|[a-z0-9-]*[a-z0-9]:(?:[\x01-\x08\x0b\x0c\x0e-\x1f\x21-\x5a\x53-\x7f]|\\[\x01-\x09\x0b\x0c\x0e-\x7f])+)\])Den Inhalt der Datei urls.txt kannst du dann vollständig entfernen und stattdessen die Daten aus der Zwischenablage wieder einfügen. Daraufhin wählst du mit folgendem "RegEx" alle Zeichen vor dem @ und das @-Zeichen selbst aus und löschst sie anschließend:
.*@Übrig bleibt eine Liste an URLs (Domains), die z.B. so aussieht, wobei pro Zeile immer genau eine URL steht:
0815datenschutzreicht.de
domain1.de
domain2.de
domain3.eu
domain3.eu
domain4.com
domain5.de
gmail.com
gmail.com
gmail.com
posteo.org
web.de
[...]Bereinige diese Datei nun um die Dupletten. Das geht unter Linux ganz einfach mit folgendem Befehl:
uniq urls.txt urls_unique.txtIn der Datei urls_unique.txt steht nun jede URL maximal einmal drinnen.
Nun sind die Vorbereitungen abgeschlossen und du kannst die Datei an mein Script übergeben.
Script
Lade dir dazu das Script smyc.sh bei Codeberg herunter und lege es im gleichen Verzeichnis ab, in welchem sich bereits die Datei urls_unique.txt befindet. Gegebenenfalls musst du die heruntergeladene Datei noch mit chmod +x smyc.sh ausführbar machen.
Starte dann das Script mit
./smyc.sh urls_unique.txtDas Script beginnt seine Arbeit und gibt dabei pro Seite ein paar Infos aus. Je nach Anzahl der URLs kann das einige Minuten dauern:
Parsing domain1.de
OK: https://domain1.de/
Parsing domain2.de
ERROR, return value for URL "domain2.de" is "Lesefehler (Die Wartezeit für die Verbindung ist abgelaufen) beim Vorspann (header). "
Parsing domain3.de
OK: http://domain3.de/
Parsing domain4.de
OK: https://www.domain4.de/
Parsing domain5.de
ERROR, return value for URL "domain5.de" is "fehlgeschlagen: Verbindungsaufbau abgelehnt. "
Parsing domain6.de
ERROR, return value for URL "domain6.de" is "http://domain6.de/: Die Datei auf dem Server existiert nicht -- Verweis ist nicht gültig! "
Parsing domain7.de
OK: http://domain7.de/
Parsing domain8.com
OK: http://domain8.com/
Parsing new URL: "https://domain8.com/"
Parsing domain9.de
OK: http://domain9.de/
[...]
Finished!Wenn das Script durchgelaufen ist, liegt im gleichen Verzeichnis wie das Script eine Tabulator-getrennte Datei namens metadata.tsv. Diese kannst du direkt mit LibreOffice oder einem anderen Tabellenkalkulationsprogramm öffnen.
Nun kannst du die Datei beliebig sortieren, die Inhalte auswerten oder einfach nur der Reihe nach die Titel, Metabeschreibungen, Autoren oder die verwendete Server-Software der Seiten studieren und staunen, mit wem das Unternehmen, von dem der Newsletter kam, so alles zu tun hat.
Viel Freude beim Erkunden 😎
Hinweis
Da oft auch persönliche E-Mailadressen von gängigen E-Mailprovidern unter den Empfänger:innen sind, können diese Provider-URLs in der Datei ebenfalls enthalten sein. Lösche die Zeilen von E-Mailprovidern wie z.B posteo.org, web.de, gmx.de, gmail.com. usw. einfach aus der Ergebnisdatei raus.
Beispielinhalt der Ergebnisdatei
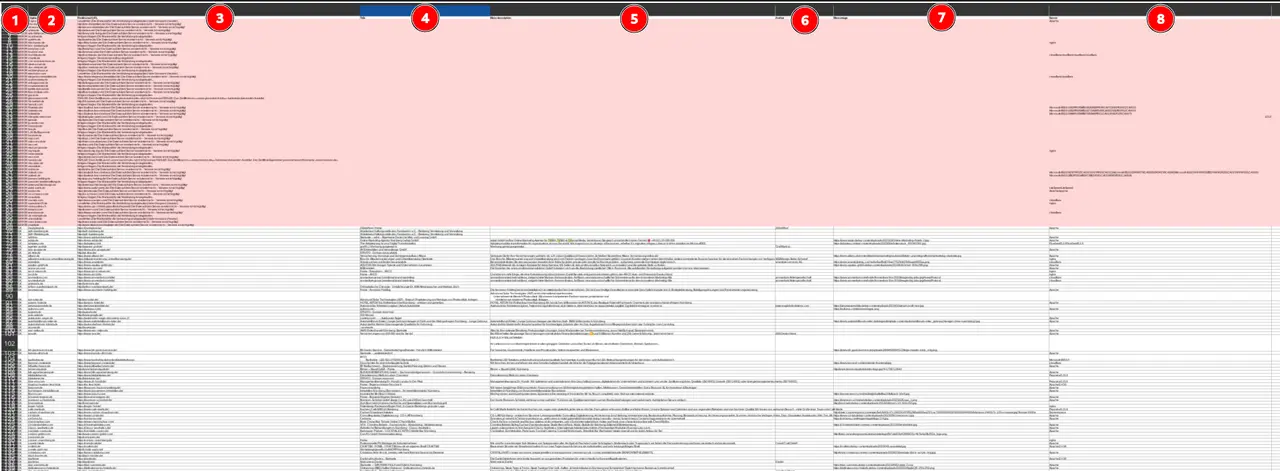
In der Ergebnis-Datei sind in den einzelnen Spalten enthalten:
- Status (
OKoderERROR) - Original URL (Die originale URL aus der Datei, die du dem Script übergeben hast)
- Redirected URL (Die "End-URL" nach diversen Weiterleitungen, andernfalls die Fehlermeldung)
- Title (Der Seitentitel, falls vorhanden)
- Meta description (Die Meta-Beschreibung, falls vorhanden)
- Author (Die Autorenangabe, falls vorhanden)
- Meta image (Die URL zum Meta-Image der Seite, falls vorhanden)
- Server (Der Name der verwendeten Server-Software, falls vorhanden)
Feedback
Ich freue mich über jede Form von Feedback und Verbesserungsideen zu meinem Script.
Schreib mir hierzu einfach über Kontakt, per Telegram oder unten in die Kommentare eine Nachricht.

 Christian Süßenguth
@sweetgood
Christian Süßenguth
@sweetgood
Hi, ich bin Christian und Inhaber der Firma SWEETGOOD. Mit dem andersGOOD Blog möchte ich auch dich für datensichere IT-Lösungen begeistern. So bringst du dein Unternehmen voran, ohne großen Konzernen deine wertvollen Daten zu liefern. Probiers mal anders!
Kommentarbereich
Die Kommentare sind für dich noch deaktiviert, da du dem Setzen von Cookies bisher nicht zugestimmt hast.
Klicke oben rechts auf "Ja, klar!" und lade die Seite neu, um die Kommentare anzuzeigen.
Seite neu laden